How the new loops in Go might become a performance trap

In the new version 1.22 of Go, a critical issue with loops, which can cause nasty bugs and unexpected behavior when capturing the reference of a variable in a range loop or when using the value in a closure, has finally been fixed.
The change
Let's take a look at the following quick example.
package main
import "fmt"
func main() {
s := []int{1, 2, 3, 4, 5}
for i, v := range s {
fmt.Printf("[%d] %d -> %x\n", i, v, &v)
}
}
Simply explained, the code iterates over the slice s and prints the index i, the value v and the address of the variable v. In Go v1.21, this would result in the following output.
[0] 1 -> c000012038
[1] 2 -> c000012038
[2] 3 -> c000012038
[3] 4 -> c000012038
[4] 5 -> c000012038
As you can see, even though different values are printed for i and v, the address of v stays the same during the iteration (actually &i would also output as the same address over the iteration). This behavior is mostly a non-issue. But if you, for example, capture v inside a closure, this will become a problem. Let's assume you wrote the following small program.
package main
import (
"fmt"
"sync"
)
func main() {
s := []int{1, 2, 3}
var wg sync.WaitGroup
wg.Add(len(s))
for i, v := range s {
go func() {
fmt.Printf("[%d] %d\n", i, v)
wg.Done()
}()
}
wg.Wait()
}
Compiled with Go v1.21, this would yield the following output.
[2] 3
[2] 3
[2] 3
Yikes! This was not the expected result.
Because v points to the same address across the iteration, the asynchronously executed closure will output the value of v as it is set right at the moment of the execution of the closure. Because the closure and the loop run in different goroutines, this will result in unexpected and unpredictable behavior.
When running the both examples in Go v1.22.0, the results would look as following.
First example:
[0] 1 -> c0000a2000
[1] 2 -> c000012038
[2] 3 -> c000012040
[3] 4 -> c000012048
[4] 5 -> c000012050
Second example:
[2] 3
[1] 2
[0] 1
That looks way better! 🎉
The fix
As described in this wiki article as well as in the Go v1.22.0 release notes, the variables in range loops are now re-instantiated in every loop run instead of being scoped over the whole loop. This also explains the output the first example displayed above where &v has a new address every time the loop has run.
Even though this change is breaking, this is a really great change. The old behavior produces way more issues when the range variables are not handled properly and the intentional usage of this behavior is probably very uncommon because of it's unpredictable nature.
But wait, when a variable, which has previously been re-used on every iteration, now needs to be instantiated every time again, doesn't this take a hit on performance? 🤔
The performance implications
First of all, the actual implementation is a bit different than described in the patch notes. In the section "Will the change make programs slower by causing more allocations?" of the wiki page, the following is stated:
"The vast majority of loops are unaffected. A loop only compiles differently if the loop variable has its address taken (&i) or is captured by a closure.
Even for affected loops, the compiler’s escape analysis may determine that the loop variable can still be stack-allocated, meaning no new allocations."
That means, as long as the loop variables do not escape the scope of the loop and the address of the variables is not taken, the new variable is allocated on the stack which is way faster than allocating on the heap, where the garbage collector needs to deal with it later on as well.
Based on this, I wrote some synthetic benchmarks to compare the performance differences between Go v1.21 and v1.22.0.
The setup
The setup is compiled of a matrix of three setups in three different use-cases.
The setups consist of the following data types used in the loops:
- Integers (
inttype) - Strings (
stringtype of length 15 to 20 characters) - Large Structs (1000
int64fields)
The use-cases consist of the following ones:
1) "Default" usage of loop variables
func Ints(s []int) {
var c int
for _, v := range s {
c = v
}
_ = c
}
2) Referencing loop variables
func IntsRef(s []int) {
var c *int
for _, v := range s {
c = &v
}
_ = c
}
3) Capturing loop variables in asynchronous closures
func IntsClosures(s []int) {
var c int
var wg sync.WaitGroup
wg.Add(len(s))
for _, v := range s {
go func() {
c = v
wg.Done()
}()
}
wg.Wait()
_ = c
}
Each slice passed to the functions has a size of 10.000 elements.
The tests presented here are executed on a bare metal Linux (Fedora 39) ThinkPad T14s with an AMD Ryzen 7 PRO 5850U and 32GiB of RAM (plugged in, set to performance power profile). Some tests you can find in the repository are also performed on a Windows workstation, but because Go programs are probably more likely to be deployed on Linux systems, I found this setup to be more representable.
If you want to dive deeper into the code, data and methodology, feel free to take a look at the repository containing the test setup. You can also run the benchmarks for yourself, if you like.
 zekroTJA
zekroTJAThe results
First, we take a look at the average runtime in nanoseconds per operation (one operation = 1 full loop though the array size; in this case 10.000 elements).
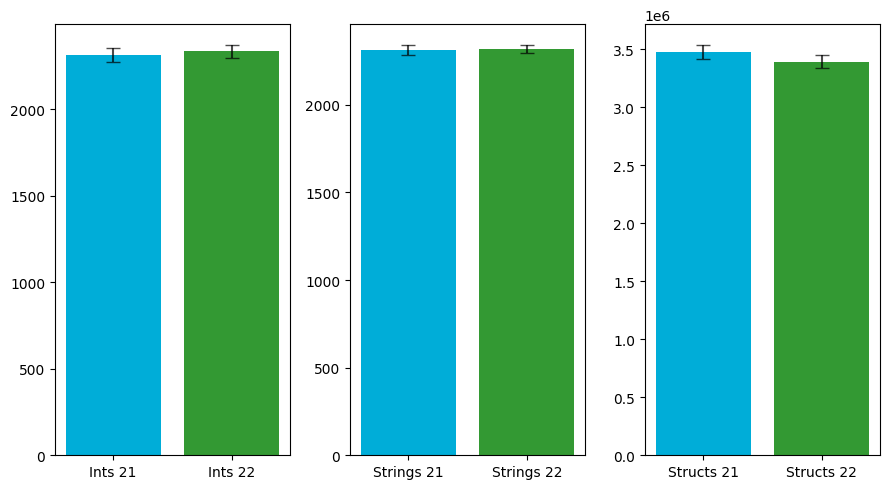
| Benchmark | Go v1.21 | Go v1.22 | Rate |
|---|---|---|---|
| Ints | 2313.30 | 2335.68 | 1.01 |
| Strings | 2311.86 | 2315.76 | 1.00 |
| Structs | 3474675.24 | 3390433.96 | 0.98 |
The first use-case, where the loop variable is only directly referenced, the runtime is very consistent across the versions. The second use-case, where the loop variable is referenced, tells another story.
| Benchmark | Go v1.21 | Go v1.22 | Rate |
|---|---|---|---|
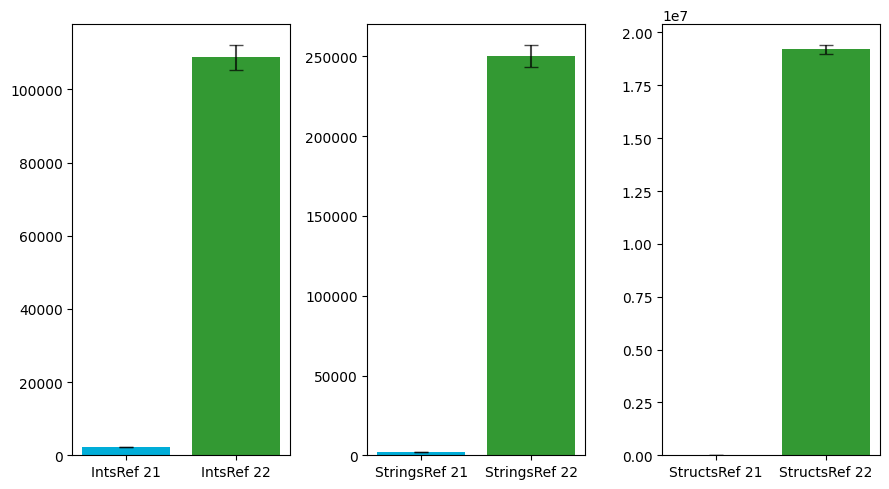
| IntsRef | 2305.54 | 108808.26 | 47.19 |
| StringsRef | 2305.28 | 250239.76 | 108.55 |
| StructsRef | 2345.00 | 19208287.88 | 8191.17 |
As you can clearly see, the runtime performance takes a huge hit when the loop variable is referenced. This factor obviously scales with the size of data, because more memory needs to be allocated on the heap, which is more time-expensive.
| Benchmark | Go v1.21 | Go v1.22 | Rate |
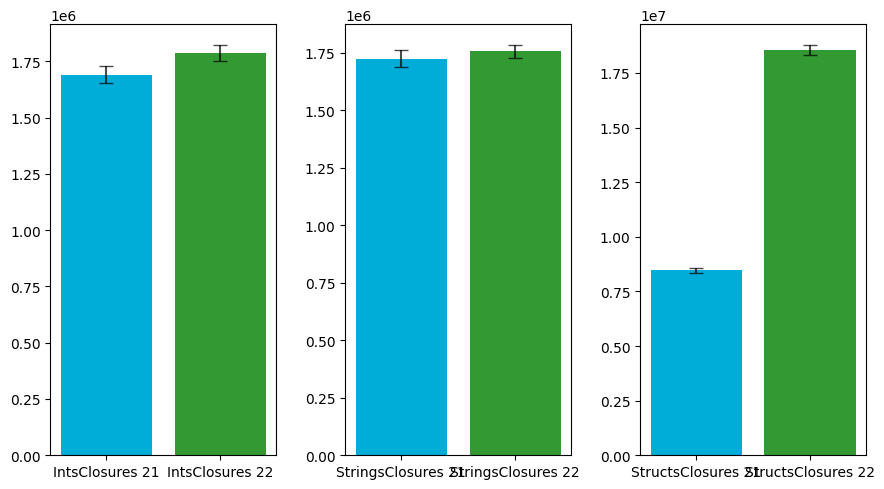
|---|---|---|---|
| IntsClosures | 1691230.26 | 1787585.46 | 1.06 |
| StringsClosures | 1722582.00 | 1756132.00 | 1.02 |
| StructsClosures | 8461972.24 | 18551921.06 | 2.19 |
The closure behavior also tells another story where the difference only shows with the large structs as values. Keep in mind that this use-cases test setup is also way more complex and expensive as the other ones because the closures need to be executed in goroutines which need to be synchronized with WaitGroups, which also adds to the time complexity.
Let's take a look at the actual average allocation amount benchmarks.
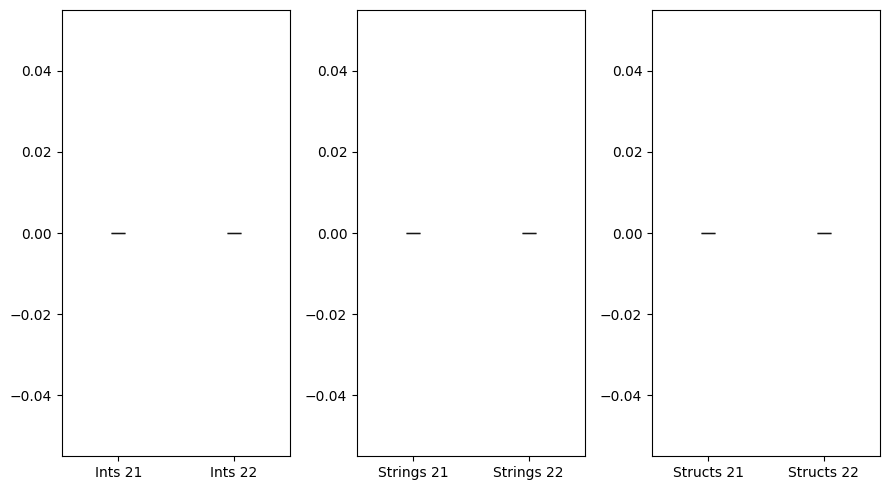
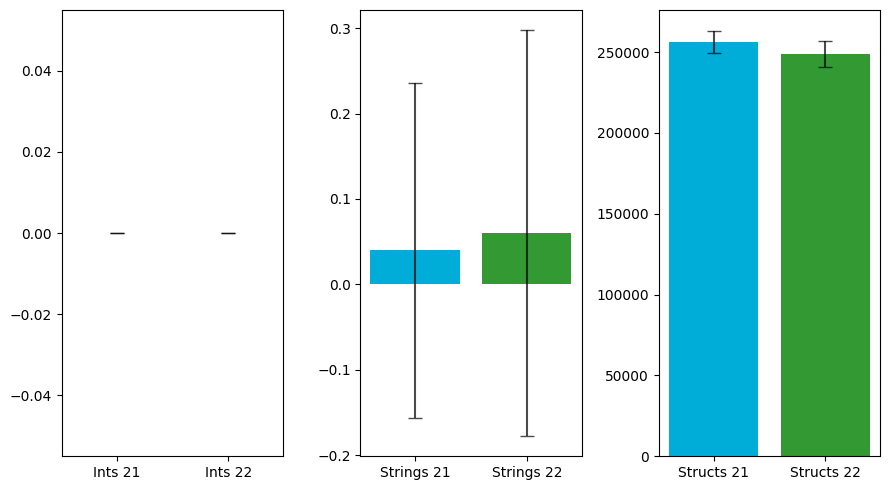
| Benchmark | Go v1.21 | Go v1.22 | Rate |
|---|---|---|---|
| Ints | 0.0 | 0.0 | 0 |
| Strings | 0.0 | 0.0 | 0 |
| Structs | 0.0 | 0.0 | 0 |
As expected, in the first use case, there are no heap allocations required for any data type in both versions.
| Benchmark | Go v1.21 | Go v1.22 | Rate |
|---|---|---|---|
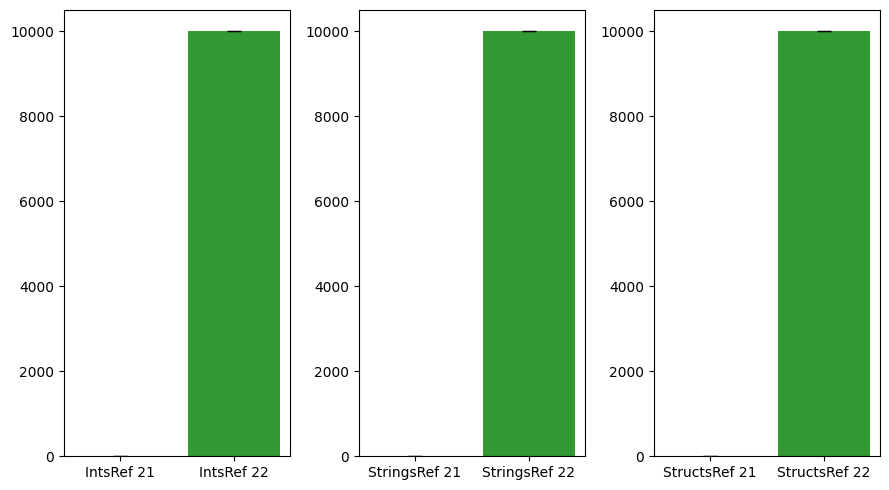
| IntsRef | 0.0 | 10000.0 | Infinite |
| StringsRef | 0.0 | 10004.0 | Infinite |
| StructsRef | 0.0 | 10000.0 | Infinite |
The second use case perfectly shows the allocations of the loop variables on the heap in v1.22 which was skipped in v1.21.
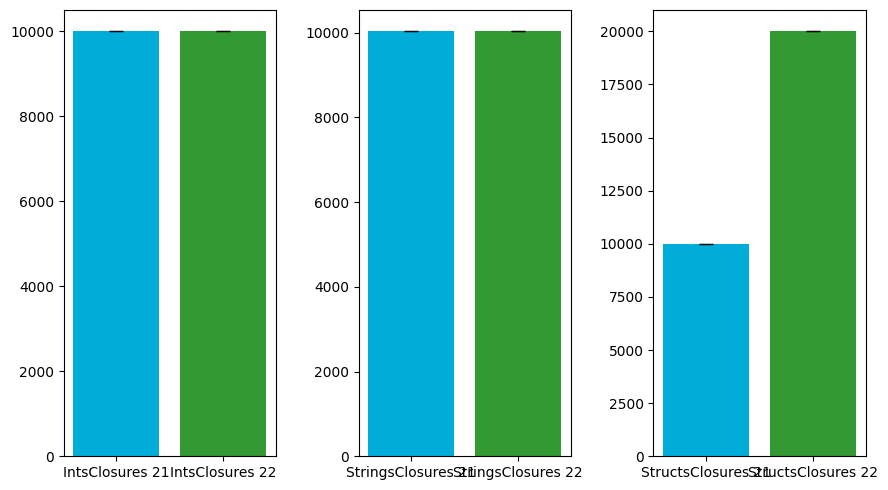
| Benchmark | Go v1.21 | Go v1.22 | Rate |
|---|---|---|---|
| IntsClosures | 10003.0 | 10002.00 | 1.00 |
| StringsClosures | 10031.1 | 10030.54 | 1.00 |
| StructsClosures | 10003.0 | 20002.00 | 2.00 |
And here, you can see the benchmarks of the average bytes allocated on each loop run.
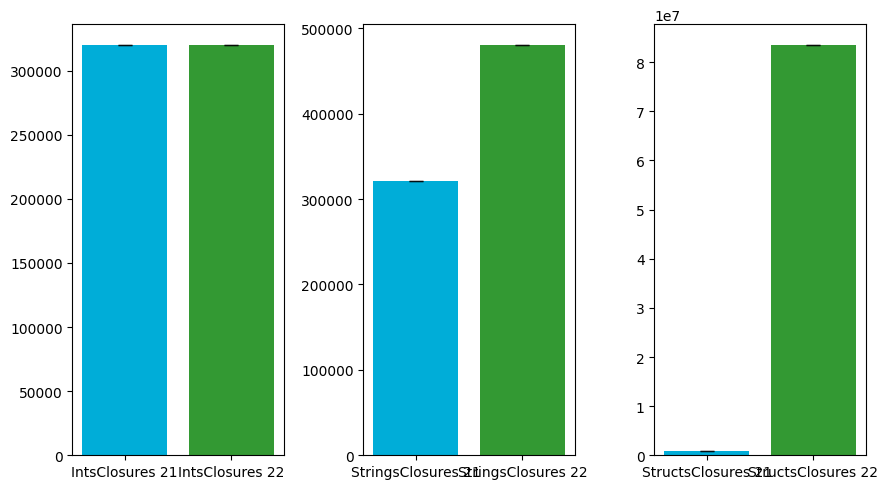
| Benchmark | Go v1.21 | Go v1.22 | Rate |
|---|---|---|---|
| Ints | 0.00 | 0.00 | 0 |
| Strings | 0.04 | 0.06 | 1.5 |
| Structs | 256121.92 | 248673.92 | 0.97 |
The first use case shows no difference in memory usage with integers and strings as values. The 1.5 increase is not really statistically relevant in this case, because the deviation is much more than the actual average. If you look at the raw data, you can see that some benchmarks allocate 1 byte of memory while some do not. Honestly, why this is like that is a mystery for me. If you have a plausible explanation for that, feel free to hit me up. 😉
The performance of structs is almost unchanged as well. The small improvement of 3% is way in the range of margin of error and so, not statistically relevant.
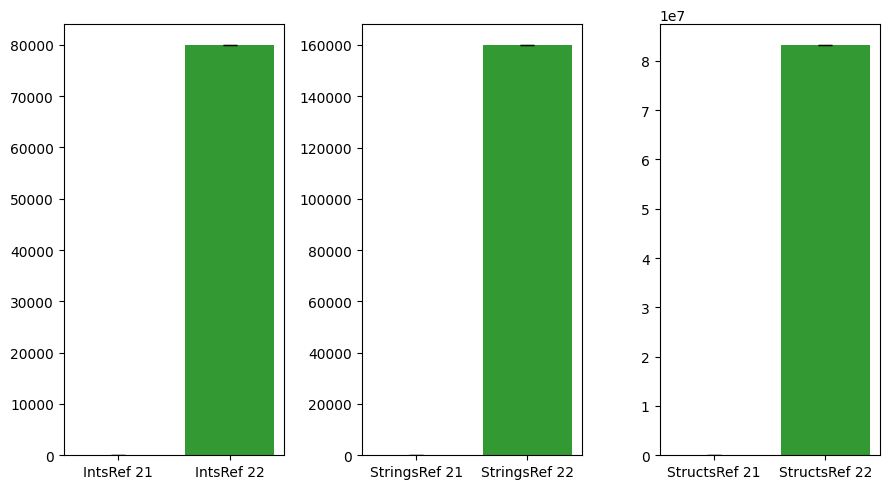
| Benchmark | Go v1.21 | Go v1.22 | Rate |
|---|---|---|---|
| IntsRef | 0.0 | 80008.08 | Infinite |
| StringsRef | 0.0 | 160106.00 | Infinite |
| StructsRef | 161.9 | 83256464.24 | 514246.23 |
The reference benchmark also tells a similar story as the other two benchmarks above. Obviously, because the benchmark setup is so simple, most of the time is spent in memory allocation instead of actual CPU work, so memory allocation and time consumption are somewhat proportional in this test setup.
| Benchmark | Go v1.21 | Go v1.22 | Rate |
|---|---|---|---|
| IntsClosures | 320158.88 | 320162.62 | 1.00 |
| StringsClosures | 320747.18 | 480755.46 | 1.50 |
| StructsClosures | 923244.12 | 83536420.56 | 90.48 |
In the closure use case, you can see that the integer test case is not affected by the change. Strings perform 1.5 times worse than before and structs perform worse with a factor of over 90. But keep in mind that the strings used in the test case are very small, so this will scale with the size of your data.
Conclusion
It was somewhat obvious that this change to loops in the new version of Go would not be for free in some circumstances, but I think, for the most common use cases, there will be no significant performance hit. To write it with the words of the Go developer team:
"Benchmarking of the public “bent” bench suite showed no statistically significant performance difference over all, and we’ve observed no performance problems in Google’s internal production use either. We expect most programs to be unaffected."
But I still think it is worth keeping in mind that, under some circumstances, the performance of your program will be impacted after this change. I think a general guideline is to avoid pulling references to loop variables out of the loop scope. Or more concise:
- Avoid taking references of loop variables when you loop over large value types.
- Avoid capturing loop variables in asynchronous when looping over large value types.
All in all, I think improving the safety and reliability of a language is always worth over some potential performance regression. So, I really like the direction the language goes and how the Go team tries to make Go more simple, safe and reliable.
If you want to learn more about the changes in Go v1.22, feel free to take a look into the following great videos.
Resources
- Go v1.22 Release Notes: https://tip.golang.org/doc/go1.22
- LoopvarExperiment Wiki: https://go.dev/wiki/LoopvarExperiment
- Benchmark Suite: https://github.com/zekroTutorials/go-range-benchmarks